Getting started
Jzab is designed for hiding the complexities of underlying Zab protocol and providing an easy-to-use user interface, but a brief understanding of Zab protocol will help you use Jzab correctly.
Overview
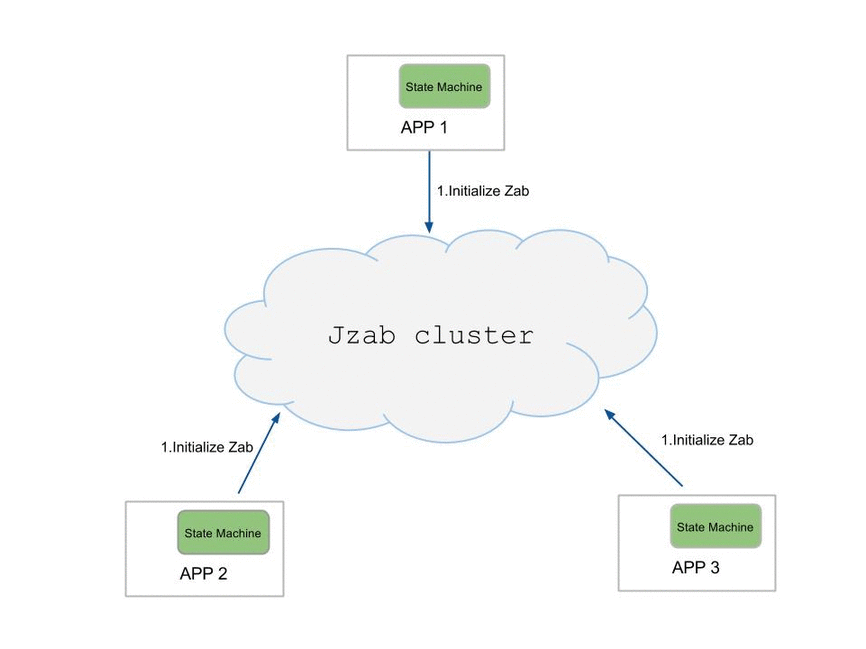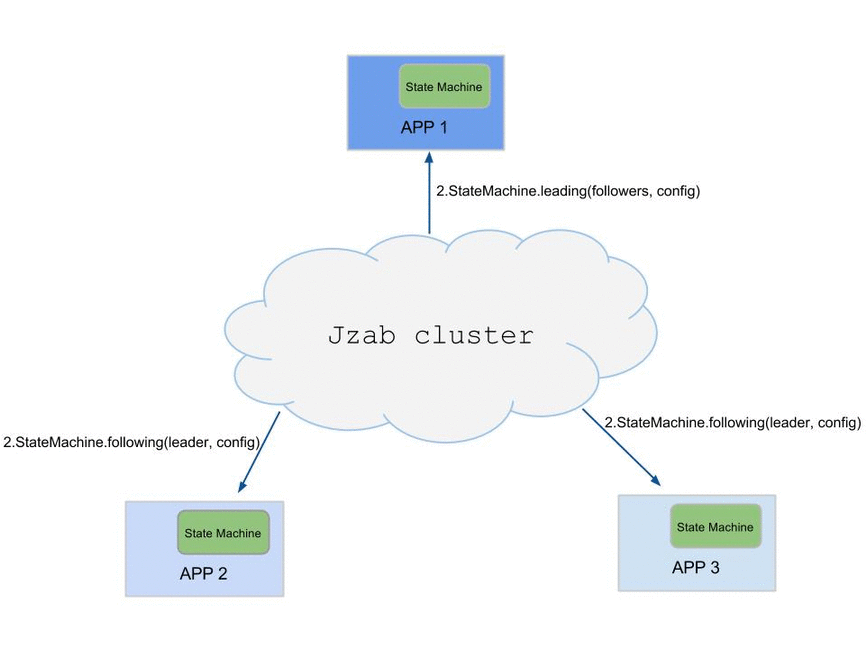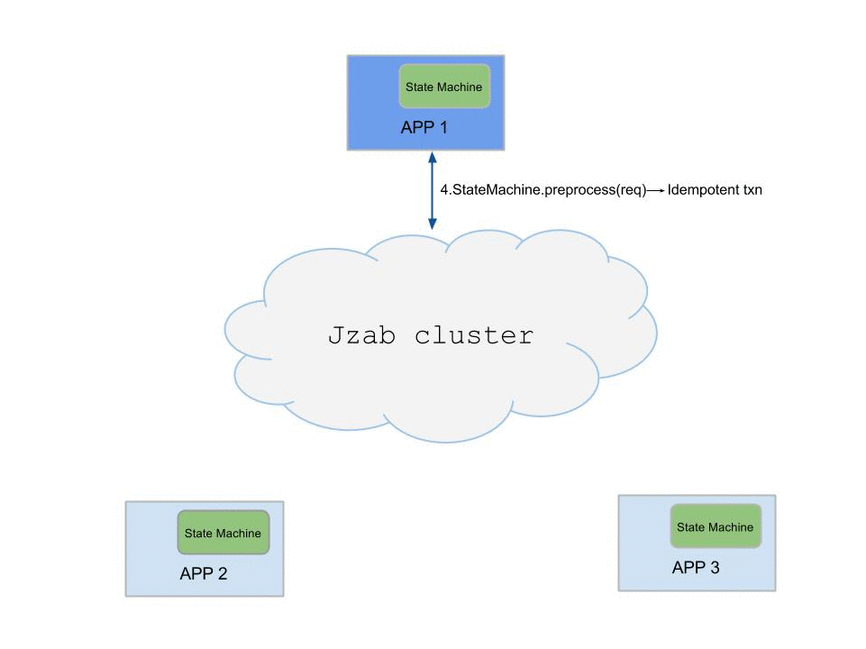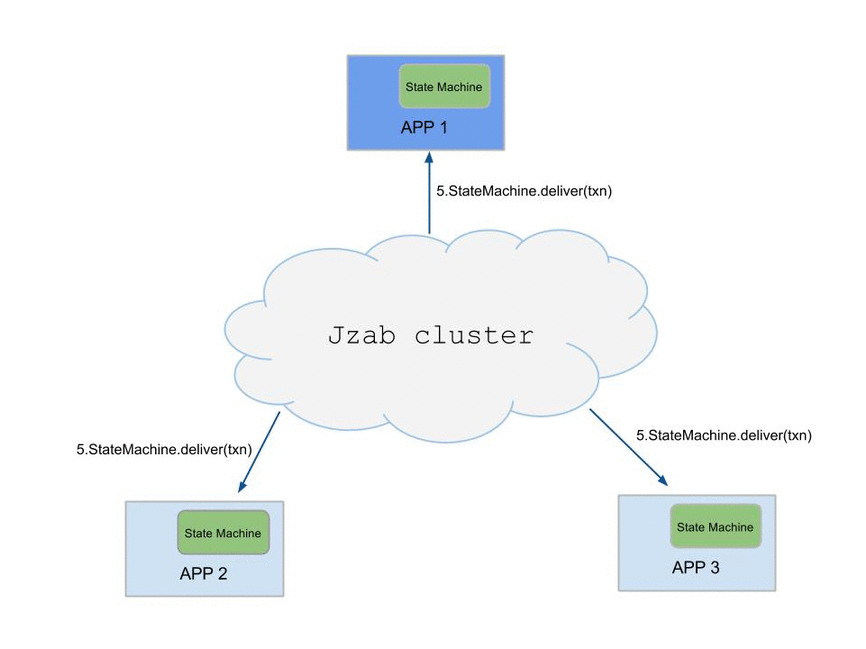
Here is a simple diagram of how an application works with Jzab. You can use Jzab to replicate state of the application consistently, which means that transactions get applied to all replicas in the same order. Transactions get persisted (i.e. fdatasync'ed) to a majority of servers before they get acknowledged to the application.
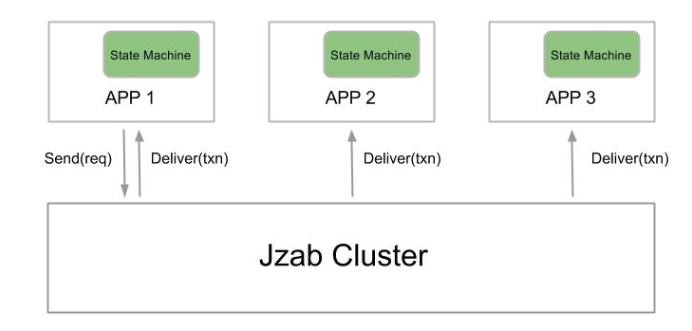
You can write the replicated application as easy as writing a standalone application. The only difference is that whenever you want to execute a command that will change the state of your application, instead of executing it immediately, you pass it to Jzab and Jzab will replicate it and deliver it back to your application when it's safe to execute.
Another thing you need to notice is that there are three states that Jzab might
be in. They are recovering, leading and following. When Jzab is in
recovering phase, any requests you passed to it will fail. Jzab will notify you
the state change via callbacks (See interface StateMachine).
![]()
This is the state transition diagram of Jzab. It begins with recovering
state, after that it goes to either leading or following state depends
on whether it's follower or leader. These two are the states Jzab will spend
most of its time in. Once leader dies or there's no quorum of servers in
cluster, Zab will go back to recovering state again.
This diagram is the typical workfolow of using Jzab.
Usage
This is the Javadoc from latest version build. For how to use Jzab, you can take a look at our reference key-value store implementation zabkv.